Why "Build vs Buy" is the Wrong Question
In big, enterprise IT departments, the question of build vs buy will often come up. A well-intentioned leader will challenge a group:
Do we really want our talented (and expensive) engineers building this thing? This doesn't feel like our competitive advantage and there must be something off the shelf we can leverage instead.
The intent of the question is good, but it lacks an important nuance. This post will describe this nuance, leveraging some very old, established ideas and my own experience.
What is our core?
The book Domain Driven Design was written in 2003 by Eric Evans. It's a book about software development, describing modelling your system to match your business domain. In a lot of ways, it's more like a book for business people who need to think about their enterprise architecture - rather than a deep technical one.
In the book, he describes the idea of a business domain. I currently work for a company whose domain is scientific publishing.
Within a business's domain though, it's broken up into smaller "subdomains" - and he identified types of them - for my current gig that's things like payroll, typesetting, editorial and so on.
These subdomains should influence whether you build or buy.
Generic subdomains (buy)
These are parts of your business that are necessary for it to function, but are not your competitive advantage.
Payroll, email infrastructure, etc. You would be foolish to invest the time, risk and so on of building these systems yourself.
It's much better to pay for someone else's expertise - it's unlikely you'll have the in-house domain knowledge to do a good job, and it presents a massive opportunity cost in terms of wasting time on something that isn't going to increase your revenue etc.
Core subdomains (build)
The opposite of the above, these are the domains that are core to your business. The more you invest and differentiate in these subdomains, the more successful your business will be, hopefully!
If you could buy your core subdomain, that means other businesses can also buy it - and compete with you more easily.
The advantage of building your own software development teams around your core subdomains is that not only do you control the knowledge and expertise, but, as it's software, you can also evolve and improve the subdomain to respond to market changes and improve profitability.
The third subdomain, "supporting"
The problem with the debate of build vs buy is it's usually argued on these battle lines, of generic and core. A binary discussion.
But Evans identified a gap in the conventional wisdom. There are domains that are not generic enough to buy off the shelf, nor valuable enough to be core.
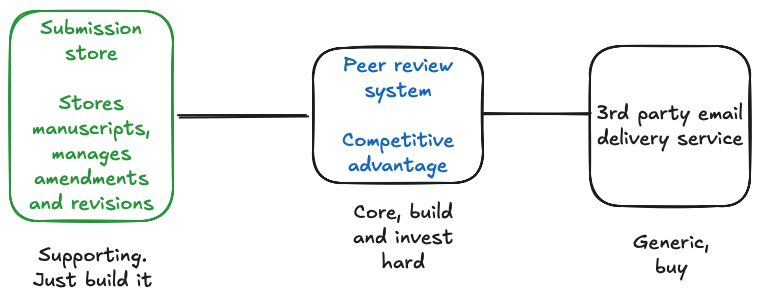
These are subdomains that will be supporting your core domains. Investing a lot of time and effort into them is unlikely to improve your business, but nonetheless they are necessary - they are a cost of doing business. If you are high enough up the org chart, you won't be aware of them (and you shouldn't!); they are there to support the core business in an unglamorous way.
The problem with vendoring a supporting domain
The logic for buying is
Don't invest engineering effort in things that aren't core
Reasonable! But when you vendor a supporting domain you are not buying expertise. Supporting subdomains tend to be quite "boring" (uninteresting, easy), something you'd expect a team even with a high degree of novices to build relatively quickly. I have read other commentary on this subject and many suggest these systems are a great way to train newer engineers.
The hidden cost of integration
Build vs buy comparisons almost always downplay the cost of integration, because the cost feels invisible down the line.
It always manifests as friction - death by a thousand cuts. Mapping complexity, lead time, vendor upgrades, misleading documentation, etc. It doesn't appear as a line item; it manifests in the business's frustration at the engineering department's capacity for work.
Additionally, to protect your core from the vendor's complexity, you tend to build a boundary around it - an adapter or anti-corruption layer that manages failure modes, absorbs breaking changes in vendor upgrades, and preserves the option to swap vendors later. This is good practice. But it is not free, and it is not counted in the line item.
There's a further irony: the boundary you build around the vendor inherits many of the same non-functional requirements you were hoping the vendor would solve. These rarely feature in the conversation, but they don't disappear just because a vendor is involved.
The gravitational pull of vendors
There's a further problem. Supporting subdomains are usually too small, trivial, and specific to have a dedicated vendor. Nobody builds their business on solving your exact problem.
So you have to buy something much larger that covers your use case incidentally - and pay for everything else indefinitely.
That excess feature surface then becomes a justification for the purchase. When we manage engineering time we try to be lean - we don't build features we don't need; we invest heavily in discovery before we commit to anything. Yet somehow in vendor discussions, hypothetical features become a reason to buy.
Are those extras really an opportunity? Or are they a sunk cost you're rationalising before you've even signed the contract?
JFDI (Just f*cking do it)
The irony is that by trying to avoid investing in a supporting subdomain, you end up investing more - just in things that have no value to your core business whatsoever.
Whereas if you just build the supporting subdomain, it's simple and unglamorous. Beyond care and maintenance, you move on. Nobody is suggesting you pour your best engineers into it forever. It's load-bearing but invisible, exactly what a supporting subdomain should be.
And the anti-corruption layer you require when using a vendor? It vanishes entirely. When you own the supporting subdomain, there is nothing to protect your core from. You are the vendor.
The obligatory AI angle
If we think through Eric Evans' lens of the types of subdomain, it becomes very obvious where you should be leveraging AI.
- Generic. The more bullish of the AI proponents argue that SaaS is doomed because we can use AI to build these things. Still, I can't see CIOs rushing to replace HR software with some vibe-coded solutions. AI does not replace expertise; it augments it. When you are buying software, you're not buying the lines of code; you're buying the expertise around it.
- Core. Yes, AI can help, but you need to handle with care. AI can accelerate delivery here, but it can't substitute for the deep domain understanding that makes your core valuable in the first place. If anything, AI makes that institutional understanding more important. More than ever, how well you understand your problem is more important than how fast you can write code.
- Supporting. Clearly this is where AI can help. The requirements are simple and stable, and tend to be similar problems others have faced in the past - problems the AI will have been trained on.
The same people shouting "use AI to go faster" are often the same people who are saying "buy don't build" for supporting subdomains - where AI would most reduce the cost of building.
Wrapping up
The next time you're in a meeting, or going through a discovery process and the argument is over build vs buy, change the frame to have a more productive discussion.
What kind of subdomain is this?
The answer won't always be obvious, and people will disagree. But without asking it, the discussion is likely to lack the nuance required to make a good decision.
In some ways core and generic are two sides of the same coin. To my business, HR software is a generic subdomain. To the people selling HR software, it is their core. This is what 'buying expertise, not code' actually means - you are buying the accumulated domain knowledge of a team that has made that problem their entire focus.
So when we ask 'what kind of subdomain is this?', the implicit question is: does anyone out there have deep expertise in this specific problem worth paying for? For generic subdomains, clearly yes. For supporting subdomains, almost certainly no - and if they do, their solution is almost certainly too large for your actual need.
Be careful not to conflate production readiness, non-functional requirements and so on as domain expertise. If you are working for a reasonably mature software development team, you should already have answers and solutions to these problems, commoditised by an internal platform.
If you are in the position of making this decision, demand clarity on what domain expertise is actually being bought. The question is: what accumulated knowledge are we paying for? Because if the honest answer sounds trivial, you are not buying expertise. You are buying complexity, which will silently choke your engineering team's capacity to do work.
References and further reading